
It seems like every major tech company out there is trying to come up with an AI chatbot of its very own. Microsoft has its fingers dipped into OpenAI and ChatGPT, thereby making it one of the biggest players in this brand new arena. Google has also entered the fray with Bard, and Microsoft is upping the ante with Bing as well by incorporating an AI chatbot into their very own property as well.
This raises the question, which AI chatbot is better than the rest? With all of that having been said and now out of the way, it is important to note that UC Berkeley tried to come up with a suitable answer by partnering with UC San Diego as well as Carnegie Mellon to form the Large Model Systems Organization, or LMSYS Org for short.
The group consists of four members of the faculty who have a specialized interest in the field of AI as well as computer science, and who engage in research in those fields. Alongside them are ten students, and these 14 individuals participated in something called a Chatbot Arena.
This allows test participants to compare and contrast two chatbots at the same time because of the fact that this is the sort of thing that could potentially end up making it easier to compare results. One thing that bears mentioning is that the participants were not told which AI chatbots they were talking to until after the test. They voted on which chatbot they preferred based on the answers they received, and the lack of knowledge pertaining to the name of the chatbot they were conversing with will have reduced bias by a large margin.
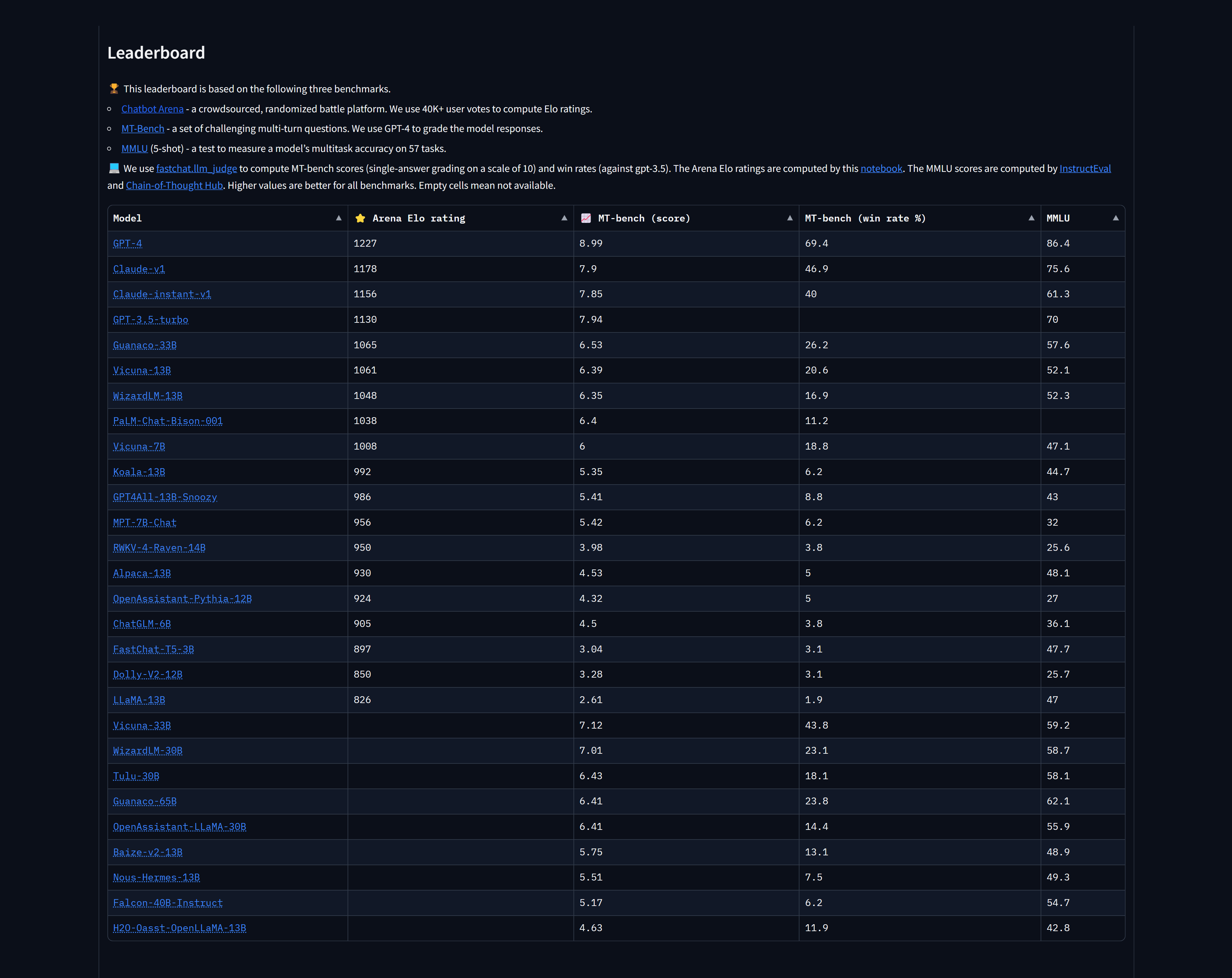
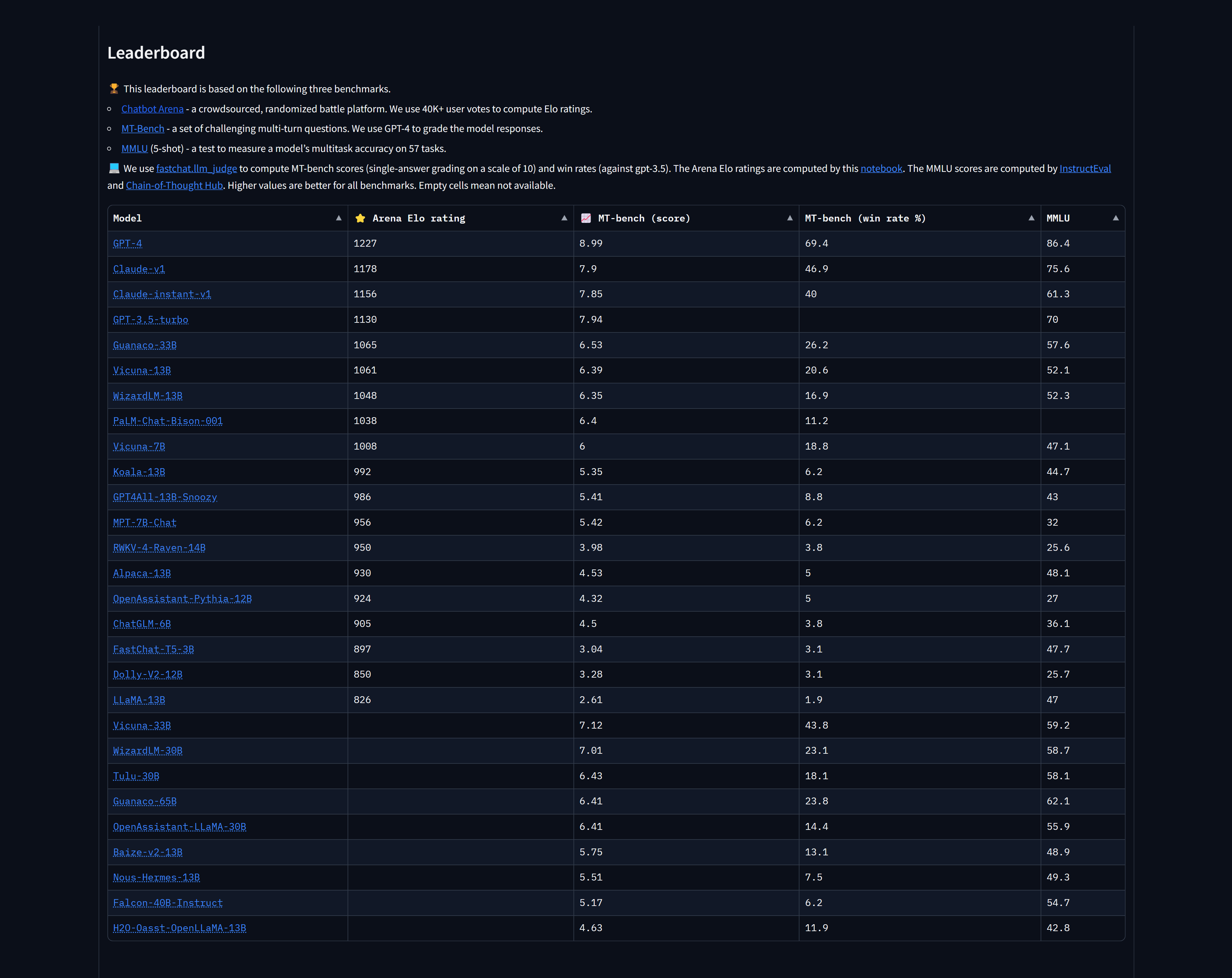
All in all, ChatGPT 4 managed to top the rankings with a score of 1,225. Claude by Anthropic came in second and third place with one version scoring 1,195 and another receiving an Elo rating of 1,153. If you don’t want to pay $20 a month for GPT 4, you can still use the free ChatGPT 3.5 which happened to rank fourth with an overall Elo rating of 1,143.
Read next: Understanding the Biases Embedded Within Artificial Intelligence
This raises the question, which AI chatbot is better than the rest? With all of that having been said and now out of the way, it is important to note that UC Berkeley tried to come up with a suitable answer by partnering with UC San Diego as well as Carnegie Mellon to form the Large Model Systems Organization, or LMSYS Org for short.
The group consists of four members of the faculty who have a specialized interest in the field of AI as well as computer science, and who engage in research in those fields. Alongside them are ten students, and these 14 individuals participated in something called a Chatbot Arena.
This allows test participants to compare and contrast two chatbots at the same time because of the fact that this is the sort of thing that could potentially end up making it easier to compare results. One thing that bears mentioning is that the participants were not told which AI chatbots they were talking to until after the test. They voted on which chatbot they preferred based on the answers they received, and the lack of knowledge pertaining to the name of the chatbot they were conversing with will have reduced bias by a large margin.
All in all, ChatGPT 4 managed to top the rankings with a score of 1,225. Claude by Anthropic came in second and third place with one version scoring 1,195 and another receiving an Elo rating of 1,153. If you don’t want to pay $20 a month for GPT 4, you can still use the free ChatGPT 3.5 which happened to rank fourth with an overall Elo rating of 1,143.
Read next: Understanding the Biases Embedded Within Artificial Intelligence
{kind=link}